.svg)
Data Quality in Early-Stage Drug Development: Paving the Way for Reliable Research Outcomes
Pawan Verma

February 23, 2024

Ensuring data quality is crucial in early-stage drug development for reliable research outcomes. This blog explores the importance of data integrity, accuracy, and completeness in identifying promising drug candidates and meeting regulatory standards. By prioritizing data quality, researchers can navigate the complexities of drug development with confidence and precision.
In real-world applications, data is often considered as ‘dirty’, making data quality a critical factor for machine learning systems to accurately predict the phenomenon that it claims to measure. In high-stakes AI applications, the importance of data quality is magnified due to its heightened downstream impact, influencing the accuracy of predictions.
Data Quality has a ‘domino effect’ where errors in data can easily propagate and have a ‘compounding’ negative downstream impact resulting in increased technical debt over time.

The above image describes common data-domino triggers that are crucial to managing any data-driven organization or while building data-intensive applications.
Characteristics of data quality can be divided into two types: intrinsic, which are qualities inherent to the data itself, and extrinsic, which are qualities not directly related to the data's inherent properties.
Intrinsic data quality characteristics are built into the data itself. Enhancing these aspects typically falls to those who generate biomedical data, such as researchers or healthcare professionals conducting studies. Once data is collected, its intrinsic quality is usually fixed and cannot be enhanced.
High-quality intrinsic data is more adaptable to various applications. Quality assurance measures taken during the collection and processing stages of biomedical data can greatly enhance its intrinsic quality. These intrinsic qualities serve as benchmarks to assess if the data meets the necessary standards for analysis.
1. Experiment Design:
2. Metadata:
3. Measurement:
Extrinsic data quality refers to the aspects influenced by the systems and procedures that engage with the data post-creation. It encompasses all elements that don't affect the data's inherent quality.
Enhancing extrinsic data quality typically falls under the responsibility of data custodians and managers, often achieved through meticulous data curation. High levels of extrinsic data quality simplify the process for users to evaluate and utilize pertinent data.
1. Standardization:
2. Accuracy:
3. Data Integrity:
4. Breadth:
5. Completeness:
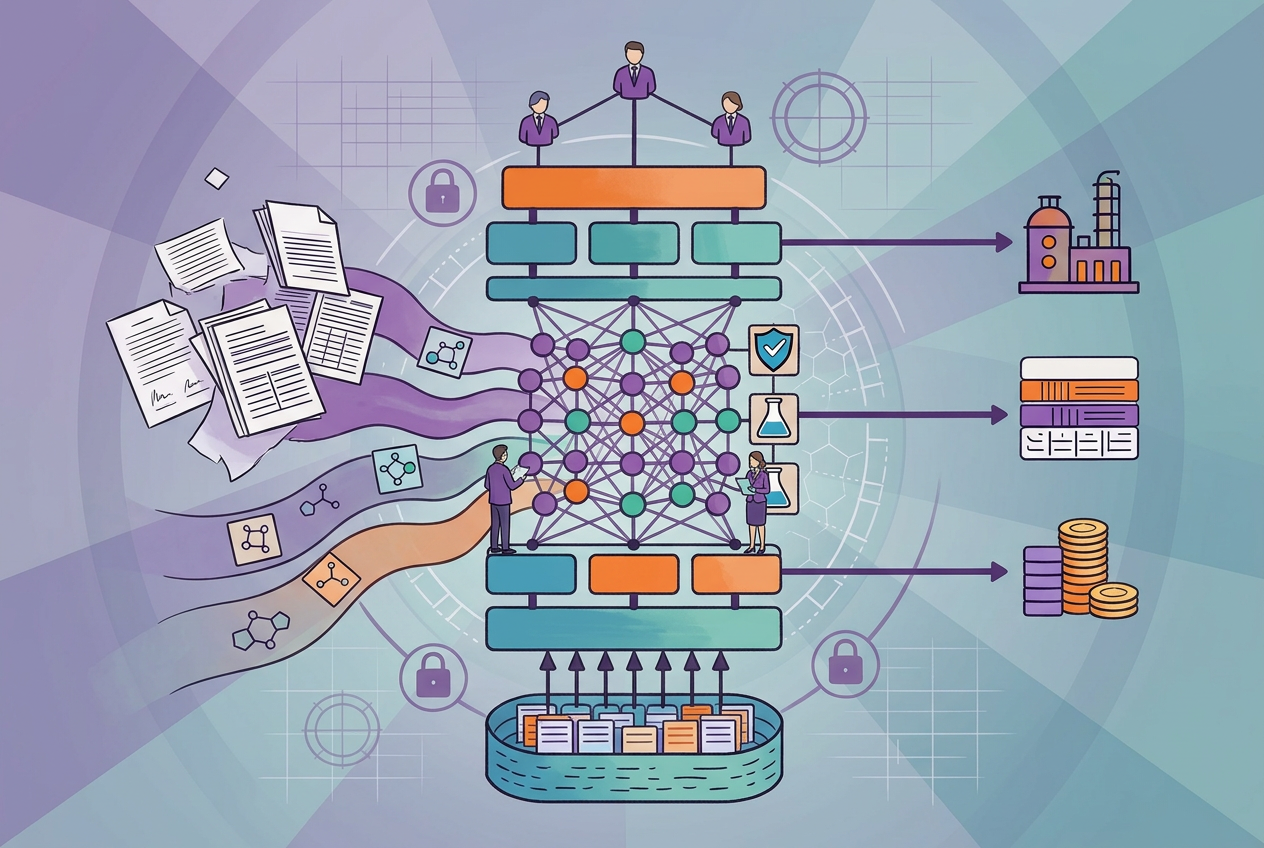
At Elucidata, data quality is ensured at nearly every stage of the data delivery process starting from its ingestion from the source to the customers’ Atlas on Polly or on a platform of choice.
Polly is Elucidata’s biomedical data harmonization platform. Polly's powerful harmonization engine processes measurements, links to ontology-backed metadata and transforms datasets into a consistent data schema.
Here’s how we ensure good data quality with Polly:
Data from various public sources often comes in inconsistent formats, making it challenging to use due to incomplete metadata annotations, which leaves out crucial context. Additionally, finding specific data within a vast collection is difficult because the descriptions of experimental setups and biological details vary greatly from one study to another, lacking a unified language.

A foundational aspect of Data Quality is the application of ontologies and standardized vocabularies for the annotation of metadata fields such as disease, organism, cell line, tissue, cell type, drugs, and various perturbations. These annotations provide crucial information about the biological entities and interventions being studied. They are essential not only for understanding the focus of the data but also for facilitating the discovery of both new and existing relevant datasets.

On Polly, the implementation of ontologies to annotate metadata fields is critical. It ensures uniformity of terminology across varied data sources and enhances the ability to efficiently navigate and interrogate the data, offering insights and connections that might not be readily apparent without this level of organization.
Ensuring data quality in biomedical research, particularly in omics studies, requires consistent processing and rigorous quality control measures. This involves the use of sophisticated bioinformatics tools and methodologies to standardize data processing, improve accuracy, and minimize technical variations.
Consistently Processed: Data must be processed uniformly to ensure comparability across different datasets. This includes using standardized protocols for data normalization, alignment, and quantification. Tools like STAR (for RNA sequencing data alignment) and Kallisto (for quantifying gene expression levels) are crucial in this step, as they provide reliable and efficient ways to process large omics datasets.
Quality-Controlled: Quality control (QC) metrics are essential to evaluate the integrity and usability of the data. QC metrics can include assessments of read quality, alignment rates, and the presence of potential contaminants. Implementing rigorous QC checks at various stages of data processing helps in identifying and correcting issues that could compromise data quality.
At Elucidata, a standardized NGS pipeline is used to process raw data from public sources such as SRA.

In organizations, where large and diverse datasets are generated from various experimental techniques, data models provide a structured framework for organizing, storing, analyzing, and interpreting complex biological information. The concept of creating “standards” through a common data model is recognized as good data management and stewardship practice.
A data standard outlines the desirable amount of information that should be captured and exposed to users for effective re-use of data.
The notion of defining standards for the sharing and reuse of biological data is not new. Over the last 20 years, several organizations and consortiums have defined standards, often called minimum information standards, for pre-clinical and clinical data. Some standards are general guidelines and outline the types of information that should be captured for data gathered using specific technologies, like MIAME for microarray data, MINESEQ for RNA Sequencing data, MIPROT for proteomics data, MIcyt for flow cytometry data, MiMET for metabolomics data, while others not only provide guidelines on the type of information to be captured but also standardize the format in which that information should be captured, e.g. MIxS for genomic data and SDTM for clinical data (CDISC).
Polly is a platform that offers machine learning-ready biomedical data from various public and private repositories. As this data is integrated into Polly and made accessible to our users, it's crucial to align the data's content with the needs of Polly's data users. Therefore, establishing data standards for Polly is essential for several reasons:
Defining data standards through a Data model contributes to the efficiency and effectiveness of research and development efforts in areas such as drug discovery and personalized medicine.
They provide a structured representation of data and its relationships, facilitating understanding, communication, and implementation.
Most importantly data models serve as a framework as to how data should be collected, harmonized, and stored for efficient retrieval and analysis.
Based on a review of available information standards for pre-clinical and clinical data, we have identified a framework consisting of the following twelve information categories to help us define the overall data standards for different types of data on Polly:

At Elucidata, we follow a holistic approach towards generating data-type specific data models. Here, not only the existing data models are reviewed, moreover, key data access patterns are identified through extensive literature review and data audits to define specific consumption journeys for different data types. In a nutshell, the consumption journey dictates the manner in which the data is modeled and stored on Polly.

At Elucidata, the emphasis on data quality is paramount, and this is reflected in the comprehensive measures taken at every stage of the data lifecycle. From the initial ingestion of data to its final delivery on Polly, Elucidata employs a multi-faceted approach to ensure that data integrity, standardization, and quality control are maintained at the highest levels.
‘Polly-verified Data’ by Elucidata stands as the gold standard in data quality for early-stage drug development. Achieving this feat involves a meticulous process on our cutting-edge biomedical data harmonization platform- Polly. Our unwavering commitment to maintaining top-notch data quality is highlighted by a thorough Quality Assurance check comprising around 50 steps, ensuring the utmost reliability and accuracy. Each harmonized dataset comes with an extensive verification report with extensive data quality and assurance checks for UMAP visualizations, gene count distributions, data matrices, metadata information and more. You can look at a sample report here.
Our Polly-verified Data epitomizes precision, adhering to stringent standards for consistency, accuracy, and completeness. Through these efforts, data on Polly not only upholds the integrity of the data it manages but also fosters an environment where data-driven insights can thrive, ultimately contributing to the acceleration of scientific discovery and innovation in the field of biomedicine.
Connect with us or reach out to us at info@elucidata.io to learn more.

.png)
.webp)

.svg)
.svg)


%201%20(1).svg)










.svg)
%20(1).svg)



