.svg)
Challenges and Opportunities of Heterogeneous Biomedical Data
Elucidata

January 19, 2022

“In today’s Big Data world, companies rely on data scientists to extract insights from their vast, ever-expanding and diversified data sets… Many people think of data science as a job, but it’s more accurate to think of it as a way of thinking, a means of extracting insights through the scientific method.”-Thilo Huellmann
In recent years, multi-omics studies such as genomics, transcriptomics, proteomics, etc. have helped scientists to derive insights into the molecular mechanism of disease progression. But each of these studies produces different types of data that differ in format and structure.
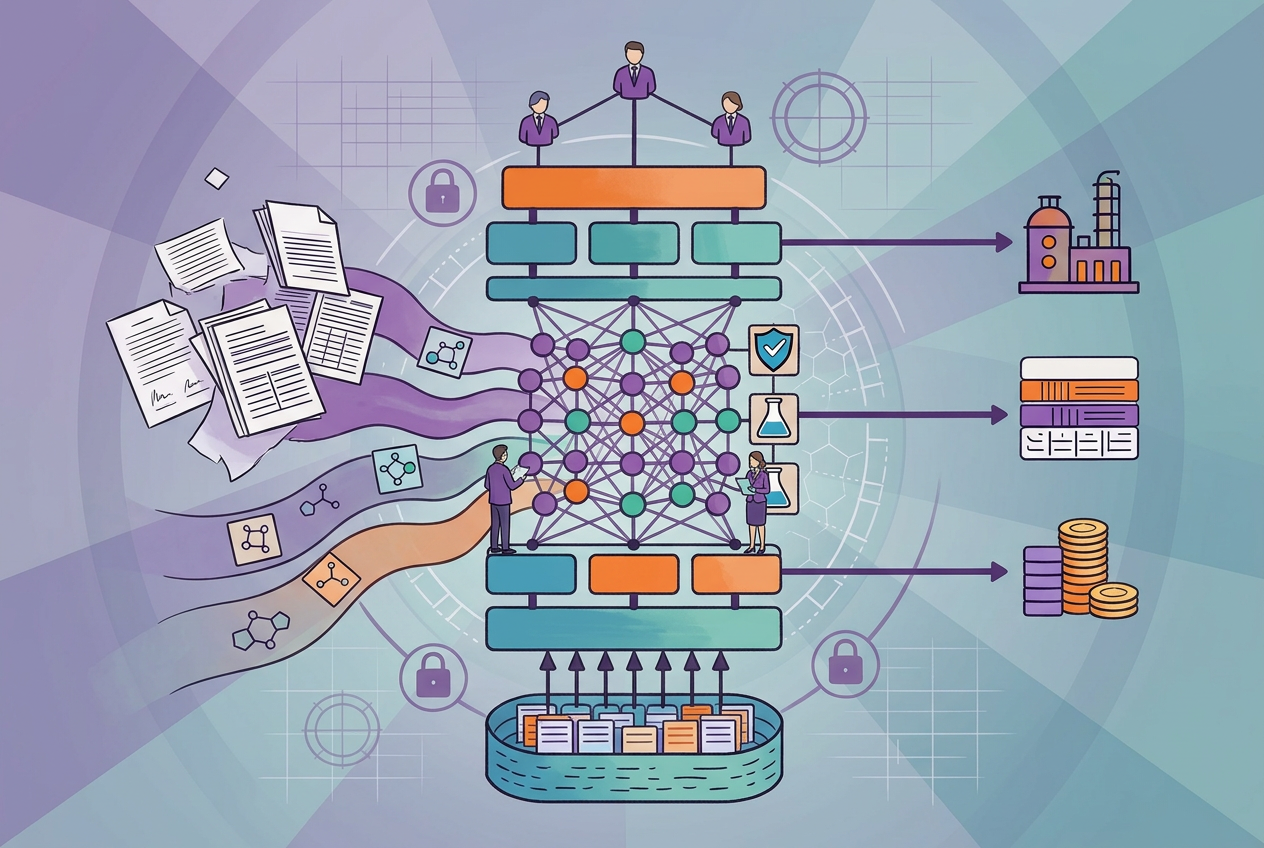
When a scientist tries to answer a research question, they invariably need to deal with the heterogeneity of different datatypes. Even a relatively straightforward transcriptomics analysis asks for dealing with several molecules and entities like transcripts/mRNAs, pathways, diseases, etc. This problem gets compounded rapidly when trying to work with multi-omics data and their analyses where one would see entities like genes, mRNAs, proteins, metabolites, pathways, diseases, etc. It becomes vital to ensure that these heterogeneous – but interconnected – entities are connected properly to unlock the full potential of the data.

According to Nilanjan Banerjee, an ML researcher at Elucidata, the industry has collectively moved toward a systems biology-focused approach, and with it, the fundamental aim of drug discovery changed. “It now aims to first understand the complex biological systems within our cells and how their dysregulation leads to disease, and finally develop methods to selectively target these systems,” says Nilanjan.
Biological networks often contain multi-scale elements, ranging from molecular components to tissues; both physical and abstract entities, ranging from proteins to phenotypic outcomes. Networks also contain diverse types of interactions between entities, such as inhibitions, activations, associations, and causal interactions.
A conventional way of gathering insights in the above scenario would require the following steps:
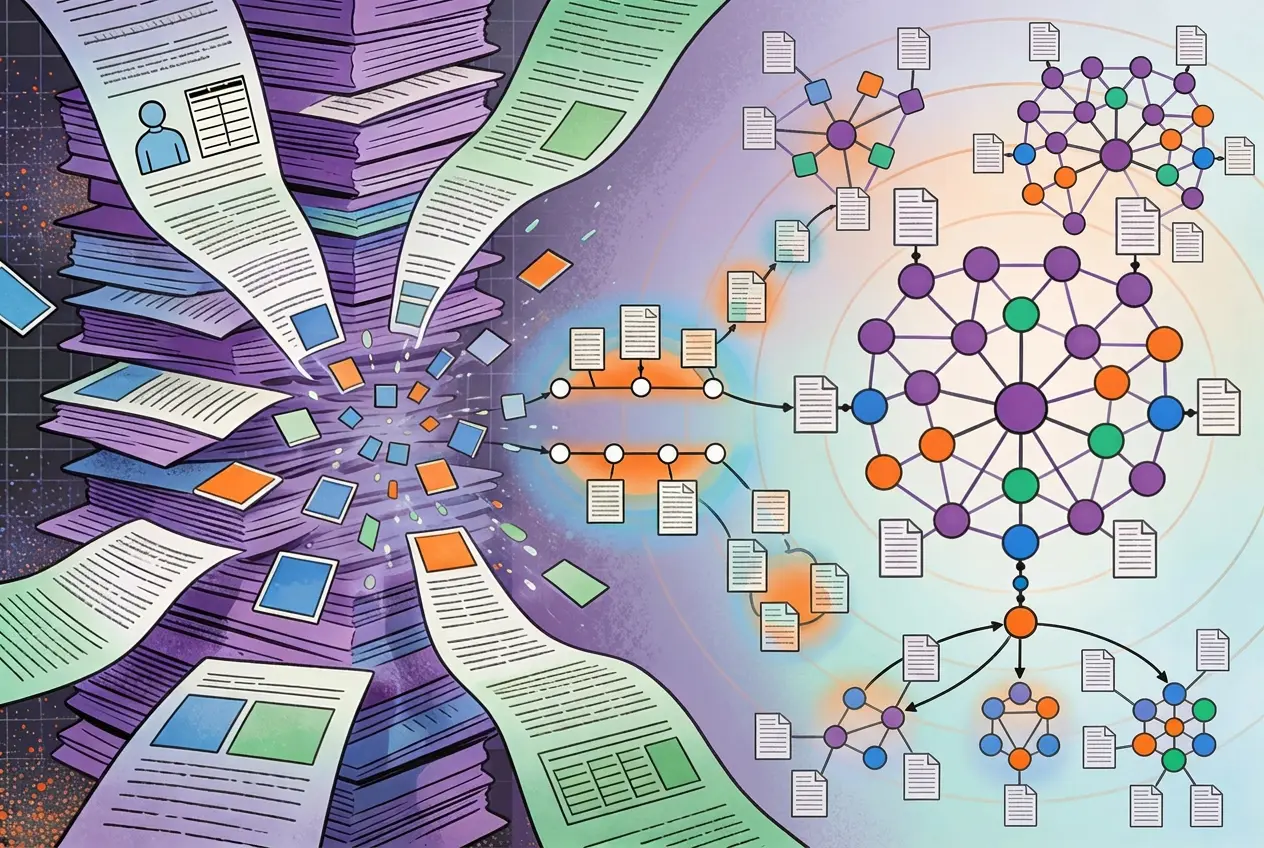
This sounds much simpler in theory. Making the leaps in deduction as listed above is a laborious and iterative process. Imagine tabulating millions of rows and trying to capture relationships amongst them. This problem only gets worse at scale. Rather than doing the exercise above one-by-one, many bioinformatics scientists are turning towards knowledge graphs (KGs). KGs help reduce the search space and provide a system-wide view of the underlying biology.

“Knowledge graphs help in integrating information from across the literature of pharmacology, genetics, and pathology.“
KGs have been around for more than 3 decades. But suitable areas of application have emerged only recently. KGs trickled down from the need of designing a framework to connect the metadata across the world wide web. Graph theorists believed that representing data as a graph makes it logically explicit and intuitive. Today, KGs have become ubiquitous. From e-commerce giants to life sciences startups, KGs have extended their reach to almost everywhere. Especially in the case of life sciences, where heterogeneity is a major challenge, leveraging KGs to extract insights out of information is a likely solution.
A few demonstrated benefits of knowledge graphs are:
It is important to remember that knowledge graphs can be used not only for querying but for knowledge augmentation as well. Research in life sciences can be siloed and over-specialized. Researchers might miss out on valuable connections between concepts that aren’t obviously related. Knowledge graphs have been promising when it comes to identifying connections between heterogeneous data points.


.png)
.webp)

.svg)
.svg)


%201%20(1).svg)










.svg)
%20(1).svg)



